Aujourd’hui, le ministre des finances du Québec, Carlos Leitao, a déposé son deuxième budget. Sur le site internet du budget on nous montre le joli graphique suivant.
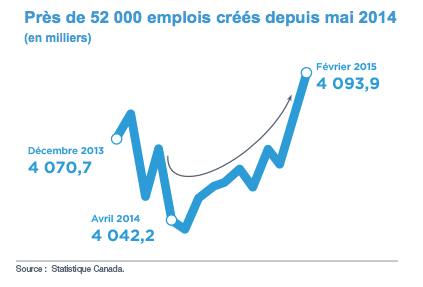
Je suis sidéré par la malhonnêteté de cette figure.
Premier problème : l’augmentation de “près de 52 000 emplois” est mesurée à partir du point le plus bas sur le graphique. Pourquoi choisir ce point de référence plutôt que décembre 2013, ou octobre 2014? Le gouvernement Couillard a été élu en avril 2014, mais l’augmentation du nombre d’emplois dans les quelques mois suivants peut difficilement être associée à des politiques qu’il aurait mis en place. Rien ne va aussi vite en politique.
Le deuxième problème est encore plus sournois. Le gouvernement québécois utilise un des plus vieux trucs pour mentir avec les statistiques : tronquer l’axe vertical pour faire paraître importante une augmentation qui en réalité n’est due qu’à des fluctuations aléatoires.
Heureusement, la source des données est citée, à savoir, Statistique Canada. Plutôt que de tomber dans le piège propagandiste du gouvernement Couillard, voyons ce que les données disent vraiment. L’information sur l’emploi est contenue dans le tableau CANSIM 282-0087 que nous pouvons facilement télécharger à partir du site de Statistique Canada. Dans un souci de transparence, je montre ci-dessous le code Python utilisé pour télécharger les données et les analyser.
import numpy as np import pandas as pd import urllib.request cansim_url = 'http://www20.statcan.gc.ca/tables-tableaux/cansim/csv/02820087-fra.zip' with urllib.request.urlopen(cansim_url) as data, open('02820087-fra.zip', 'wb') as f: f.write(data.read()) !unzip 02820087-fra.zip
Le tableau est assez volumineux une fois décompressé (environ 217 Mo). Le code suivant lit le fichier et extrait l’information concernant le Québec. Le tableau de données étant bizarrement structuré, il faut faire un peu de nettoyage pour obtenir les données qui nous intéressent.
date_parser = lambda x: pd.to_datetime(x, format='%Y/%m') raw_data = pd.read_csv('02820087-fra.csv', sep=';', encoding='iso-8859-1', names=['date', 'geography', 'characteristics', 'sex', 'agegroup', 'datatype', 'vector', 'coord', 'val'], skiprows=1, parse_dates=['date'], decimal=',', na_values={'val': 'x'}, date_parser=date_parser) quebec_data = raw_data[(raw_data.geography == 'Québec') & (raw_data.sex == 'Les deux sexes') & (raw_data.agegroup == '15 ans et plus') & (raw_data.datatype == 'Désaisonnalisées')] popn = quebec_data[quebec_data.characteristics == 'Population (x 1\xa0000)'].loc[:, ('date', 'val')] emploi_tplein = quebec_data[quebec_data.characteristics == 'Emploi à temps plein (x 1\xa0000)'].loc[:, ('date', 'val')] emploi_tpartiel = quebec_data[quebec_data.characteristics == 'Emploi à temps partiel (x 1\xa0000)'].loc[:, ('date', 'val')] clean_data = pd.merge( pd.merge(popn, emploi_tplein, on='date'), emploi_tpartiel, on='date') clean_data.columns = ['date', 'popn', 'emploi_tplein', 'emploi_tpartiel'] clean_data.set_index('date', inplace=True) clean_data['emploi_total'] = clean_data.emploi_tpartiel + clean_data.emploi_tplein
Nous pouvons maintenant reproduire le graphique du gouvernement. Nous traçons le nombre d’emplois total en fonction du temps pour la période allant de décembre 2013 à février 2015 en prenant soin de restreindre l’axe vertical à l’intervalle entre 4 030 et 4 100 (en milliers).
import matplotlib.pyplot as plt %matplotlib inline import seaborn as sns sns.set_style('ticks') sns.set_context("talk") clean_data.emploi_total[clean_data.index >= '2013-12'].plot(lw=10, grid=False) sns.despine(offset=10)
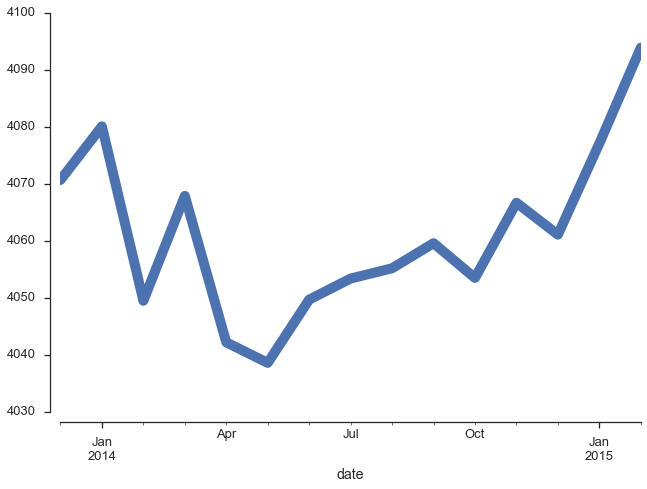
C’est bel et bien le graphique que nous montre le gouvernement. Maintenant, voyons la réalité. Tout d’abord, si nous ne trichons pas en tronquant l’axe vertical, voici à quoi ressemble l’évolution du nombre d’emplois.
clean_data.emploi_total[clean_data.index >= '2013-12'].plot(grid=False) plt.ylim((0, 4500)) sns.despine(offset=10)
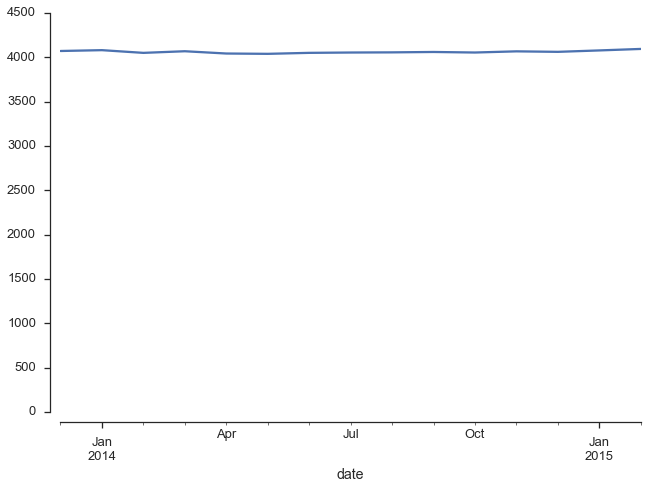
Hum… un peu moins impressionnant. Pourquoi? Parce que l’augmentation que semble voir les yeux croches du gouvernement Couillard n’est pas réelle. Le nombre d’emplois est à peu près constant depuis décembre 2013. S’il y a une tendance à l’augmentation, elle est beaucoup plus faible que ce que ne laisse croire le graphique du gouvernement (et n’oublions pas que la population augmente elle aussi).
Ensuite, nous pouvons regarder sur une échelle temporelle un peu plus grande. Le graphique ci-dessous montre l’évolution du nombre d’emplois depuis la crise de 2008. J’y ai également indiqué les dates des deux dernières élections.
clean_data.emploi_total[clean_data.index >= '2008-01'].plot(grid=False) marois = "2012-09-04" couillard = "2014-04-07" plt.annotate('Élection du gouvernement Marois', xy=(marois, clean_data.emploi_total[clean_data.index == "2012-09-01"].ix[0]), arrowprops=dict(arrowstyle='-|>', linewidth=1), size=14, xytext=(-250, 40), textcoords="offset points") plt.annotate('Élection du gouvernement Couillard', xy=(couillard, clean_data.emploi_total[clean_data.index == "2014-04-01"].ix[0]), arrowprops=dict(arrowstyle='-|>', linewidth=1), size=14, xytext=(-120, -80), textcoords="offset points") sns.despine(offset=10, trim=True)
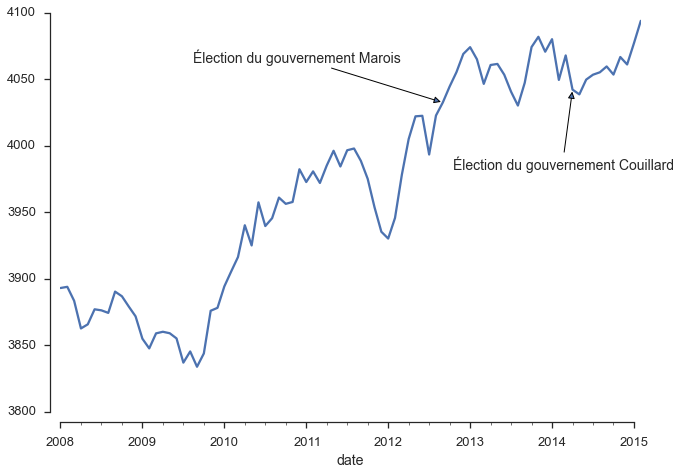
Depuis 2008, la tendance est à une augmentation du nombre d’emplois. Ce qui se passe depuis l’élection du gouvernement Couillard ne fait que s’inscrire dans cette tendance générale. Nous constatons aussi que les fluctuations aléatoires sont importantes (de l’ordre de 20 000 emplois) ce qui confirme que le changement du nombre d’emplois depuis 2013 est minime.
Alors un conseil pour le gouvernement Couillard : révisez votre façon de présenter des données et arrêtez de prendre les québécois pour des niais.